
Data Quality
Data quality at the highest level is one of the basic prerequisites for valid business decisions.
Data quality is a multidimensional construct that is determined by several measurement variables. The individual processes, use cases, users and systems in each organization determine which dimensions are relevant for the data quality in each data set.
GIn general, a high level of data quality is the basis for true data intelligence and thus a fundamental success factor for all data-driven business processes and models. Increasing your data quality creates the optimal conditions for smart decision-making processes and top performance in the digital age.
Check out our tool for the optimization of your data quality:
DATAROCKET Core
The prelude to a successful data management project
Performing a data analysis is a suitable measure to start a master data management project. It gives you an initial overview of the quality level of your data in its current state and allows you to plan further steps based on this knowledge.
Our approach to data analysis:
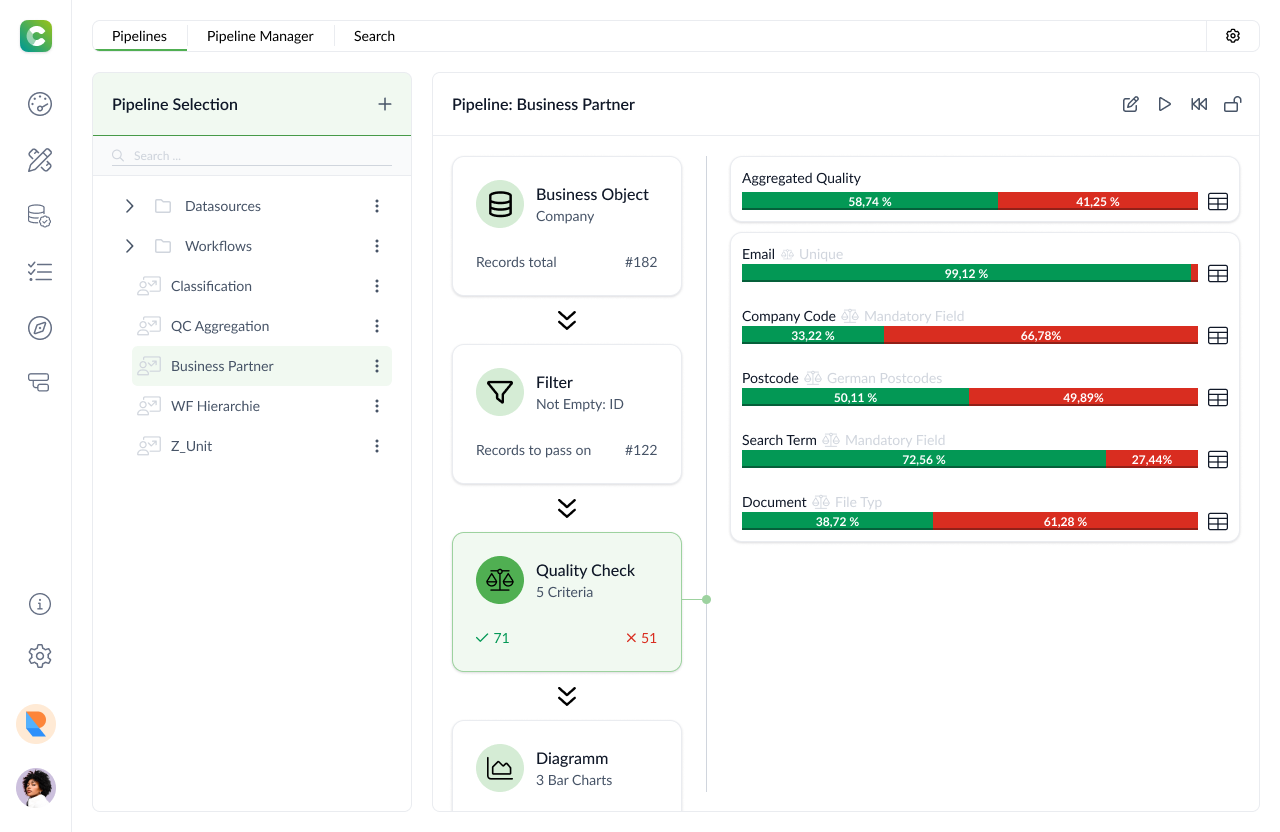
We proceed on a field basis. Based on pipelines the data quality can be determined with which you can define individual quality criteria and calculation paths. We carry out individual quality audits for each of our customers. To enable us to build up customer-specific sets of data quality criteria faster and more efficiently, we use templates developed in-house. We offer data quality rule templates for creditor data, debtor data and SAP material data.

Phase 1:
Development of measurement and analysis structure
Design and implementation of a DQ system
Requirements elicitation methodology
Structured measurement framework (DQ system)
Technical specifications for attribute maintenance
Company-wide standards for ensuring data quality
A data quality system (regulatory framework) is created to support employees in implementing and complying with the defined standards and rules.
Phase 2:
Implementing the Data Quality Measurement
Select relevant attributes
Define quality criteria
Establish duplicate definition rules
Determine key performance indicators to measure data quality
Determine required data exports
Result: The structured analysis measures the data quality in the company and is a prerequisite for the long-term implementation of quality criteria.
Benefits and results of measuring Data Quality
1. Check for duplicates
Identify duplicates based on specified criteria.
Use intelligent matching to identify similarities.
Merge duplicates by selecting relevant information.
Ability to manually review and correct potential duplicates.
2. Data Quality check
Data validation: Checks for validity according to defined rules.
Plausibility Check: Check for logical consistency and inconsistencies.
Completeness check: Check for the presence of all required fields and the absence of empty values.
Consistency check: Compare with other data sources to detect inconsistencies.
Purge functions: Automatically cleanse data, add missing values, correct invalid values, adjust formatting, and remove duplicates.
3. Optimization
Analyze data to identify weaknesses and patterns of data quality issues.
Provide metrics and assessments to quantify and evaluate current data quality.
Identify root causes of data quality problems.
Provide specific data cleansing and optimization recommendations.
Cleansing
Optimized data quality through data cleansing
Usually, data cleansing is the first approach to restore a correct database as the foundation for improving data quality. Detection and elimination of duplicates plays a decisive role, as does the establishment of validation rules for measuring data quality and monitoring its success.
The duplicate detection, which you can perform with our master data management software DataRocket, checks the entire data set and finds entries that concern the same business object but contain different information. In a process called data harmonization, these entries are merged into one comprehensive, meaningful data set – the Golden Record.
Golden Record
DATAROCKET Core acts as a hub in a company’s data landscape and as such accesses heterogeneous data sources. The data records from these sources are extracted and consolidated and then merged into Golden Records. This Golden Record or single point of truth is a master data record that combines the relevant attributes from all data sources.
Not only the elimination of duplicates, but also other corrections improve the data quality:
Plausibility violations (e.g. the net weight must always be less than the gross weight of an article)
Filling levels and limit values such as minimum and maximum values (e.g. postal codes with a fixed amount of digits)
Missing standards for date formats, addresses or phone numbers
Data Cleansing with DATAROCKET Core
Automated data cleansing
The application of one or more previously defined rules results in updated data (bulk update).
Data cleansing workflow
A workflow is run through in the software and manual corrections are made to the data based on the results.
Mass update (bulk upload)
A new file with clean data is uploaded to update the data set.
Long-term data quality improvement
DATAROCKET Core offers real-time measurements for continuous monitoring of data quality in your company. The innoscale mdm software DataRocket measures and continuously monitors the current data quality directly in your systems. The measurement provides results for the following quality criteria, among others:
Timeliness and age of the data
Consistency, validity, accuracy, completeness and uniqueness
Frequency of change
Read more in our blog
Our blog covers Master Data Management, use cases and white papers for successful enterprise MDM projects.


